- Advertising
- Bare Metal
- Bare Metal Cloud
- Benchmarks
- Big Data Benchmarks
- Big Data Experts Interviews
- Big Data Technologies
- Big Data Use Cases
- Big Data Week
- Cloud
- Data Lake as a Service
- Databases
- Dedicated Servers
- Disaster Recovery
- Features
- Fun
- GoTech World
- Hadoop
- Healthcare
- Industry Standards
- Insurance
- Linux
- News
- NoSQL
- Online Retail
- People of Bigstep
- Performance for Big Data Apps
- Press
- Press Corner
- Security
- Tech Trends
- Tutorial
- What is Big Data
NoSQL Performance: Measuring Couchbase Performance with Couchdoop
Calin-Andrei Burloiu, Big Data Engineer at antivirus company Avira, and Radu Pastia, Senior Software Developer in the Big Data Team at Orange, are the team behind Couchdoop - a high performance connector for bridging Hadoop and Couchbase.
Calin and Radu ran their CDH + Couchbase setup on the Full Metal Cloud and documented the performance of Couchdoop, when varying environment parameters. These are their findings.Use caseAvira’s large scale applications have a traditional 2-tier architecture:• Analytical tier built around the Hadoop ecosystem which crunches large amounts of user event logs. We use Cloudera’s Distribution of Hadoop (CDH).
Real-time tier which exposes web services to almost 100 million users. This tier requires a high performance database, and we decided to use Couchbase, which is known for its sub-millisecond response time. However, when we tried to integrate the two technologies, Hadoop (CDH) and Couchbase, we soon reached the conclusion that current solutions just created a bottleneck. So we decided to write our own and Couchdoop, a high performance Hadoop connector for Couchbase, was born.

Calin-Andrei Burloiu, Big Data Engineer at antivirus company Avira, and Radu Pastia, Senior Software Developer in the Big Data Team at Orange, are the team behind Couchdoop - a high performance connector for bridging Hadoop and Couchbase.
Calin and Radu ran their CDH + Couchbase setup on the Full Metal Cloud and documented the performance of Couchdoop, when varying environment parameters. These are their findings.
Use case
Avira’s large scale applications have a traditional 2-tier architecture:
• Analytical tier built around the Hadoop ecosystem which crunches large amounts of user event logs. We use Cloudera’s Distribution of Hadoop (CDH).
• Real-time tier which exposes web services to almost 100 million users. This tier requires a high performance database, and we decided to use Couchbase, which is known for its sub-millisecond response time.
However, when we tried to integrate the two technologies, Hadoop (CDH) and Couchbase, we soon reached the conclusion that current solutions just created a bottleneck. So we decided to write our own and Couchdoop, a high performance Hadoop connector for Couchbase, was born.
Couchdoop allows us to both import data from Couchbase into any HDFS storage, and also to export from Hadoop into Couchbase. Couchdoop leverages Hadoop parallelism, so it is ideal for doing fast batch loading of data. For simple tasks and prototyping, Couchdoop may be used as a command line tool, but for more complex tasks it may be used as a Hadoop MapReduce Java library. For more information on Avira’s use case for Couchdoop, check out our article on the Cloudera’s blog.
We benchmarked Couchdoop on Bigstep’s Full Metal Cloud and, besides evaluating Couchdoop itself, the experiments also allowed us to push Couchbase to its limits, by leveraging Hadoop’s parallelism.
In the next sections we will describe how we tested Couchbase and Couchdoop, then we’ll look over some charts to evaluate the performance and in the end we will cover some issues and limitations that we encountered.
Experimental Setup: Infrastructure
Both Hadoop and NoSQL databases perform significantly better on non-virtualized systems, so for this experiment we used Bigstep’s Full Metal Compute Instances. All nodes had the same configuration:
• 2x Intel E5-2690 2.9 GHz CPU for a total of 16 physical cores (32 virtual cores because of Hyper-Threading)
• 192 GiB of RAM DIMM 1600MHz
• Local hard-disks
• 4 x 10Gbps Ethernet
For Hadoop, we deployed CDH version 5 (Cloudera Distribution Including Apache Hadoop) on 7 worker nodes. The Couchbase cluster was provisioned on separate nodes running Couchbase Server 2.5. We used 2 Couchbase nodes at first, but later on, we leveraged the scalability of the Full Metal Cloud to provision an additional Couchbase node within minutes, so that we could also measure the performance benefits of adding an extra Couchbase node.
What we tested
The experiments tested two features of Couchdoop:
• exporting data from a Hadoop storage to Couchbase;
• importing data from Couchbase by using views into a Hadoop storage.
For both features we used HDFS as Hadoop storage, but Couchdoop allows the of use any other storage (such as HBase) by setting a different InputFormat (for exports) or OutputFormat (for imports).
What we varied between tests
During our tests we experimented with two variables:
• the level of parallelism, that is, the number of Hadoop tasks from which we performed the import / export;
• the number of Couchbase nodes used in the database cluster.
The first metric above can be easily varied when running Couchdoop jobs. So we run experiments with 1, 2, 4, 8, 16, 32, 64, 128, 256 and 384 Hadoop map tasks. Hadoop was run on YARN, which allocates tasks to available containers. Each node has a limited number of containers. That’s why, as we will see in the next section, there is a limit in the number of tasks that may run simultaneously on the cluster.
In order to vary the second metric we required to provision a new node and to perform a rebalance in Couchbase, that’s why we only tried to experiment with 2 and 3 Couchbase nodes. Luckily, provisioning new nodes with Bigstep is very easy.
How we ran the tests
To provide statistical significance, each experiment was repeated 10 times.
The data used in our experiments was comprised of JSON documents which had about 2.2 KiB each. The data was generated by a script which created JSON records with a few fields populated with random lines of text from a book. This ensured that each JSON document is unique.
Each import experiment pulled about 7 GiB of data from Couchbase. Couchdoop allows to control the level of parallelism by setting the number of Hadoop map tasks to be used for the import. For more details, check “Importing” section of Couchdoop’s documentation.
In order to be able to control parallelism for the export experiments we used a variable number of HDFS input files, which have at most the block size. FileInputFormat will use a map task for each file, so the number of input files equals parallelism value. As a consequence, as the parallelism value increases, the size of the data which is pushed to Couchbase also increases, linearly. So there was a difference between imports and exports in the experiments. Imports worked with constant amounts of data, while for exports the amount of data was variable.
Experimental Results
Let’s look at each test that we run (remember that each test was repeated 10 times, and what you see plotted is the average for those 10 repetitions).
Exporting from Hadoop to Couchbase (3 Couchbase nodes)
1 Hadoop mapper
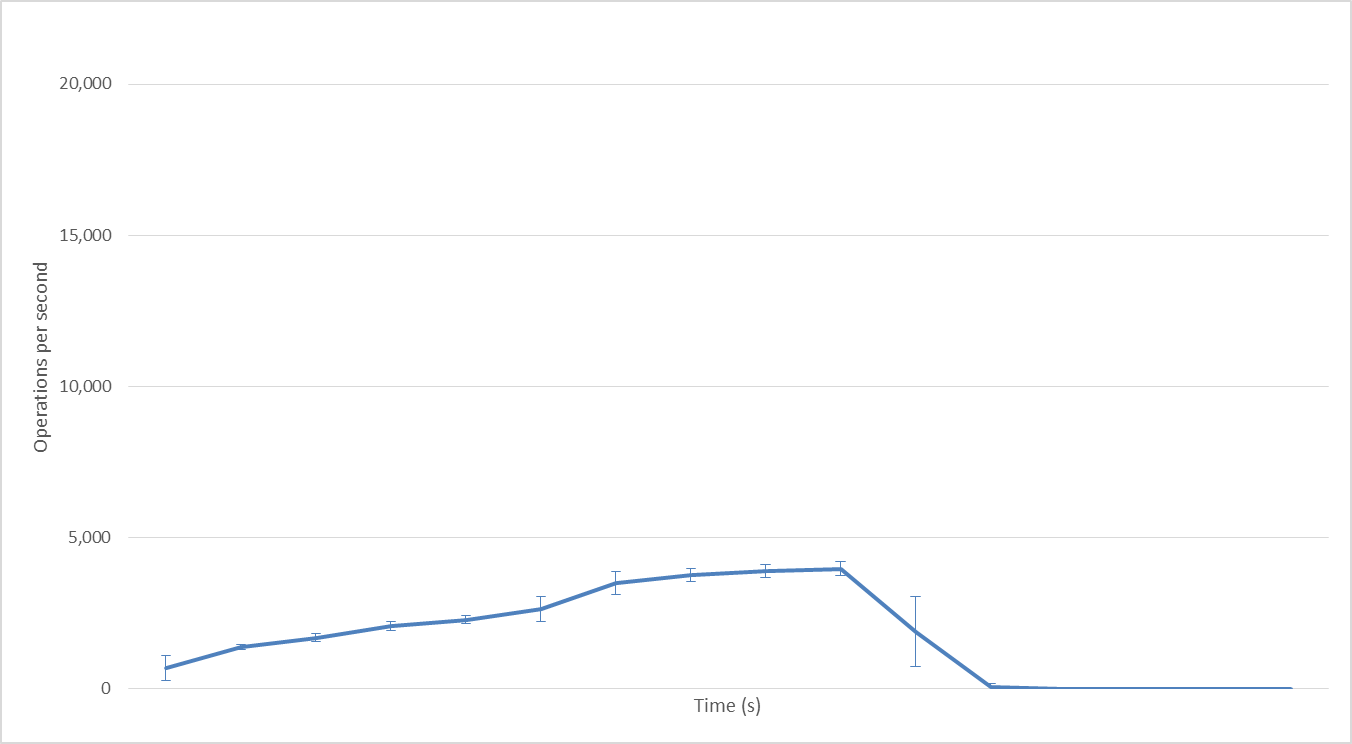
With 1 Hadoop mapper: there is no parallelism, since there is just 1 mapper; operations per second rise steadily up to 4000 ops/second.
2 Hadoop mappers
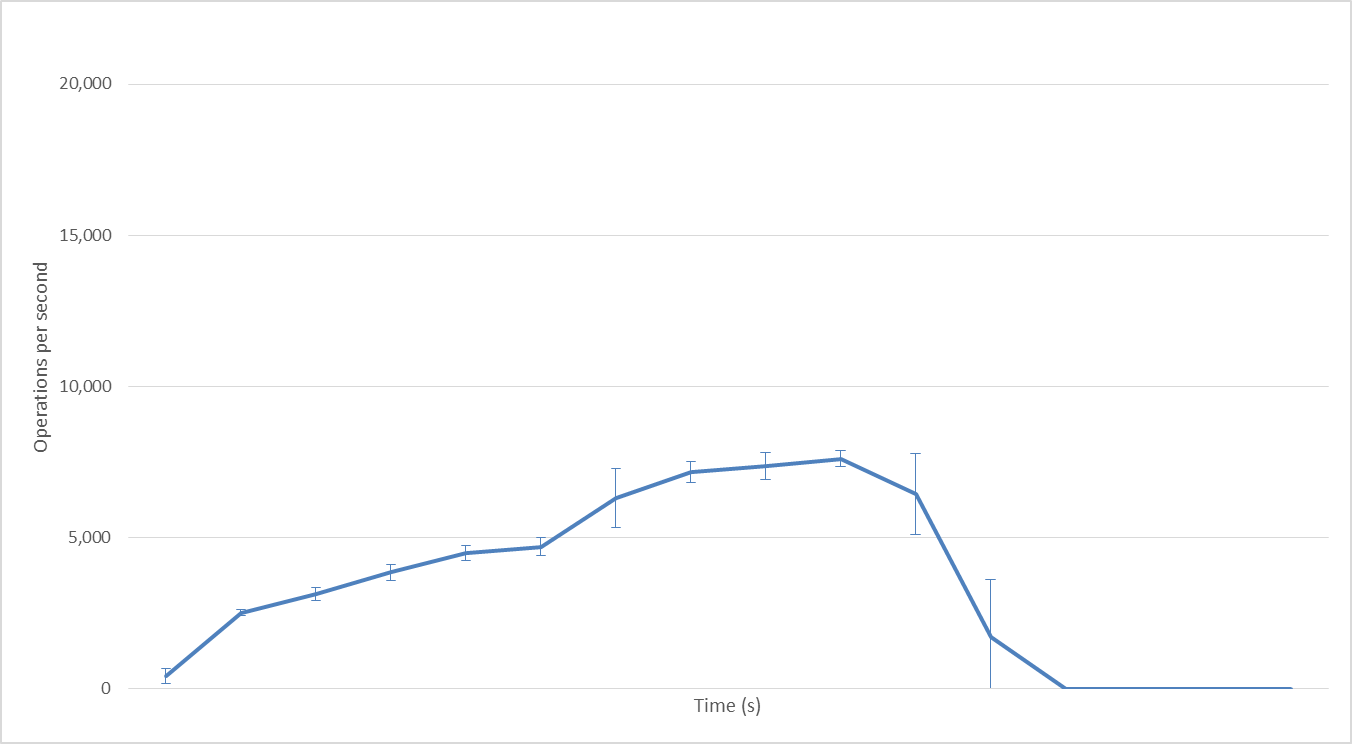
With 2 Hadoop mappers: adding another mapper introduces parallelism; performance peaks at 7000 ops/second. With 8 mappers we got 20,000 ops/second; performance increase is not quite linear but pretty much what we expected.
128 Hadoop mappers
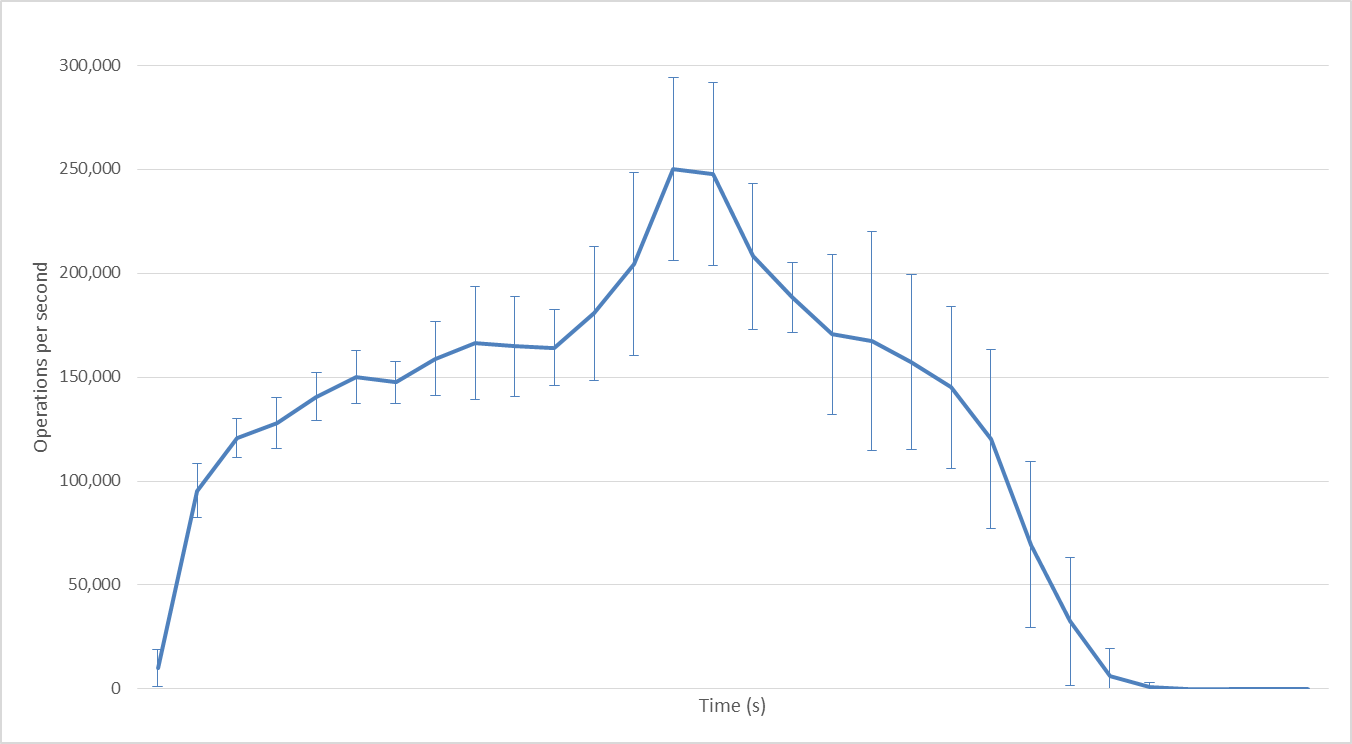
With 128 Hadoop mappers: we exceed 200,000 ops/second.
384 Hadoop mappers
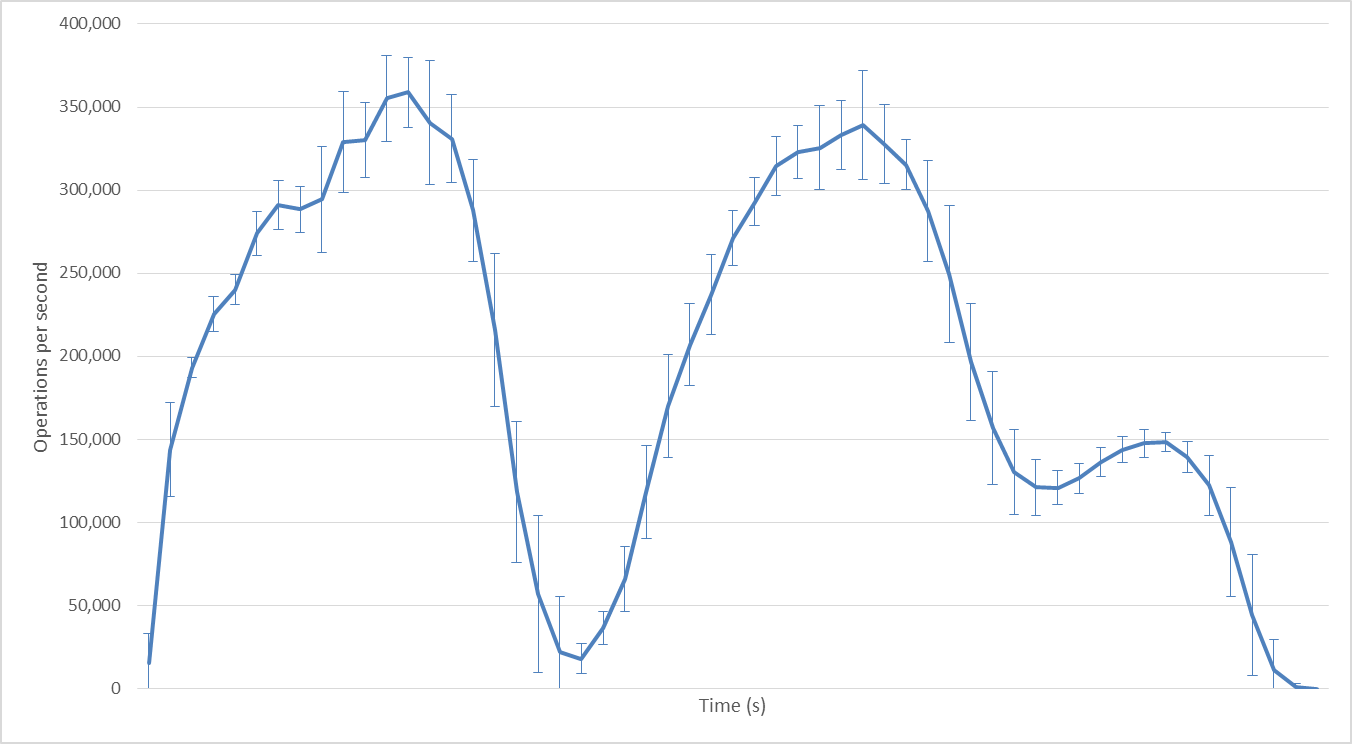
With 384 Hadoop mappers: the number of mappers exceeds the number of task slots available on our cluster; we can see how two waves of mappers are executed one after the other; performance peaks at 340,000 ops/second. Because the number of task slots is fixed, further increasing parallelism would have no effect on performance.
All exports to 3 Couchbase nodes
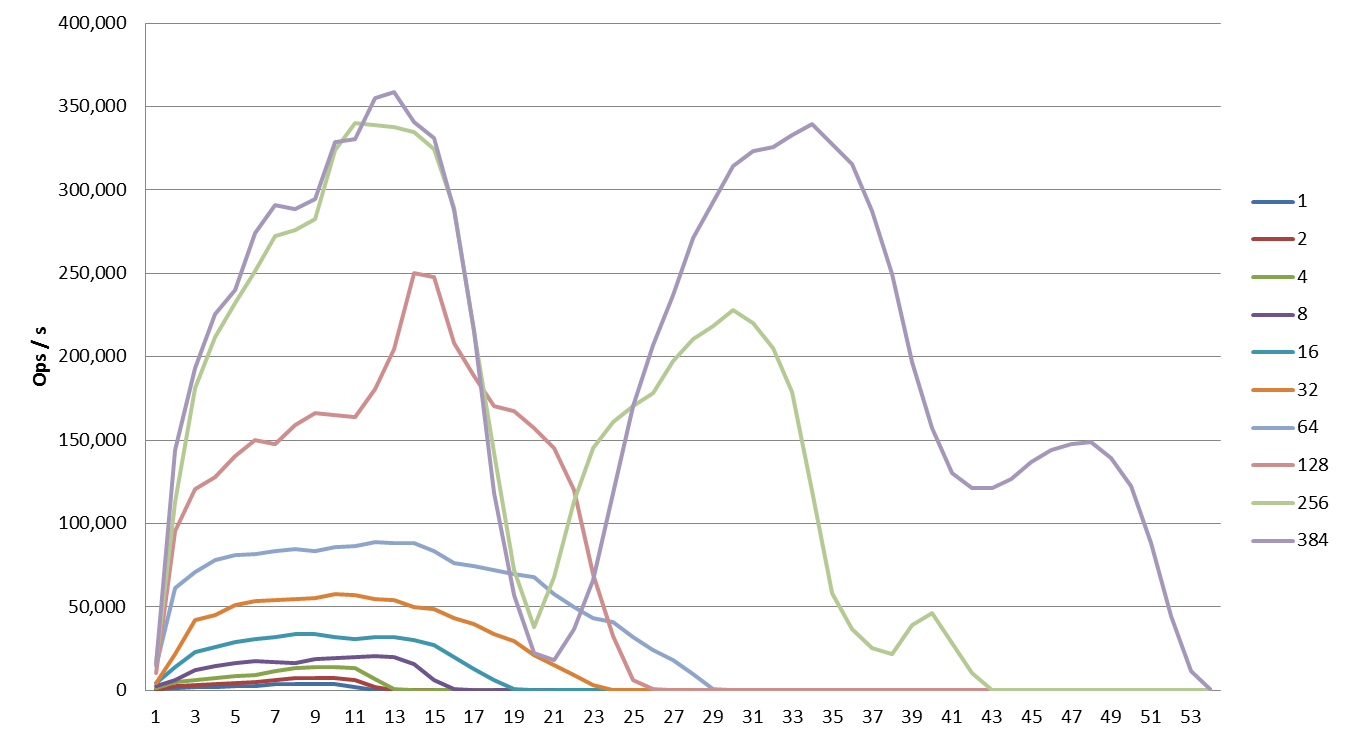
All export tests are shown on the same graph. Please mind that the total test data exported in each test run was not the same, but rather directly proportional with the number of mappers (due to the way we have setup our scripts). This is why the jobs with more mappers achieve greater performance but do not finish faster (because there is also more data to export).
Export performance dependence on the level of parallelism
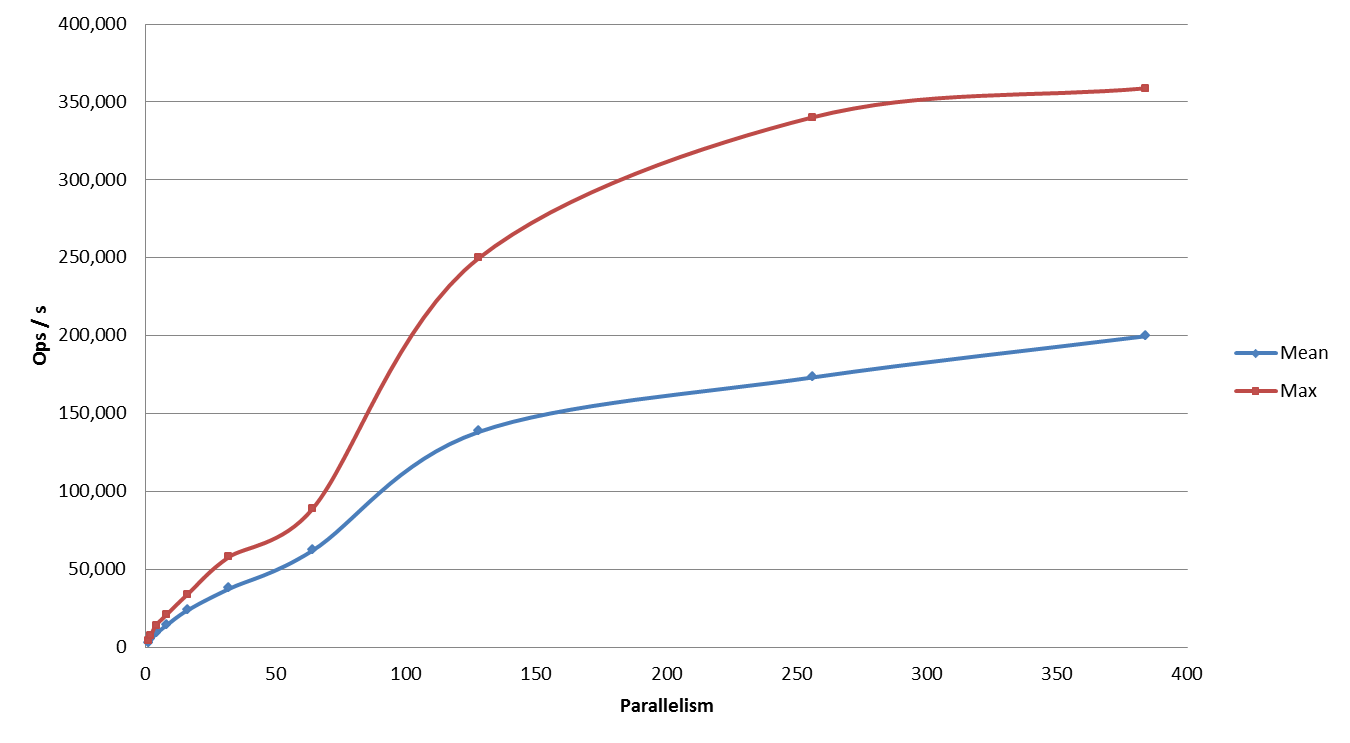
Export performance increase plotted against the level of parallelism.
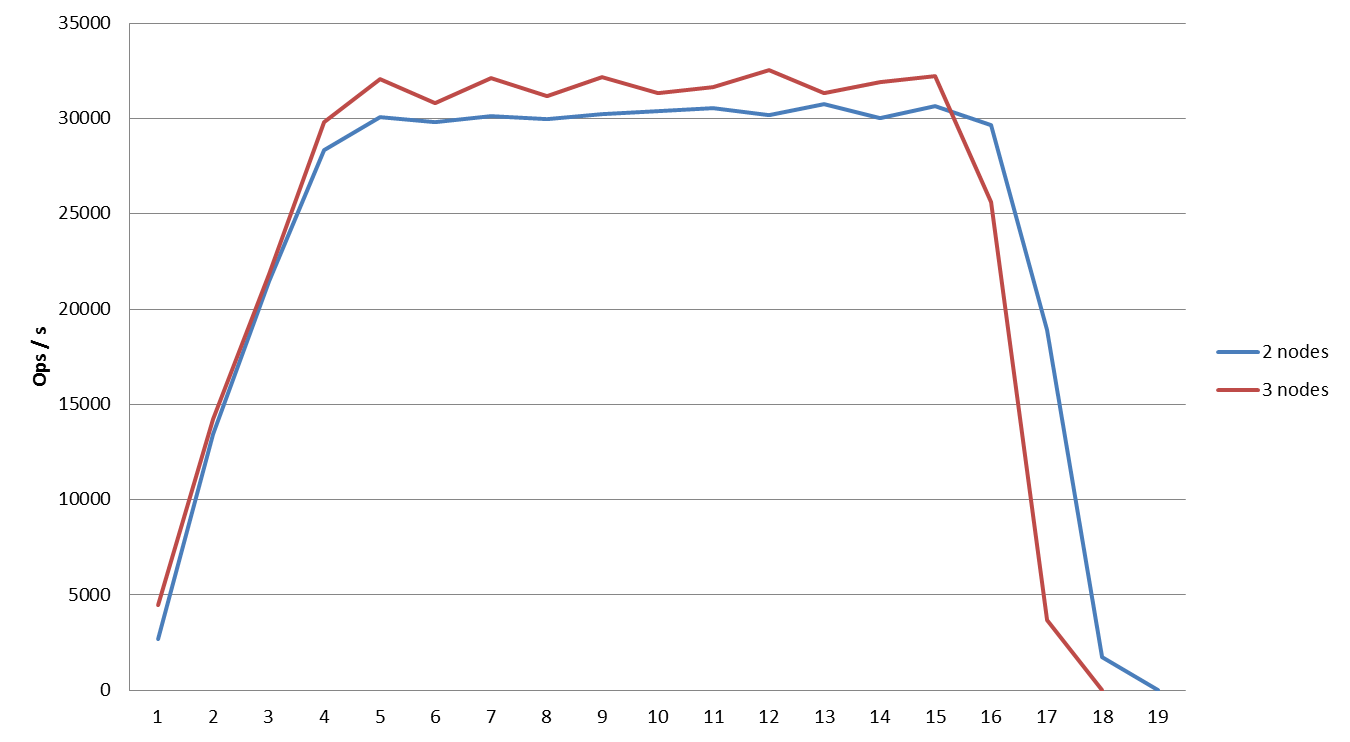
Comparing performance when exporting to 2 and 3 Couchbase nodes from 32 Hadoop mappers
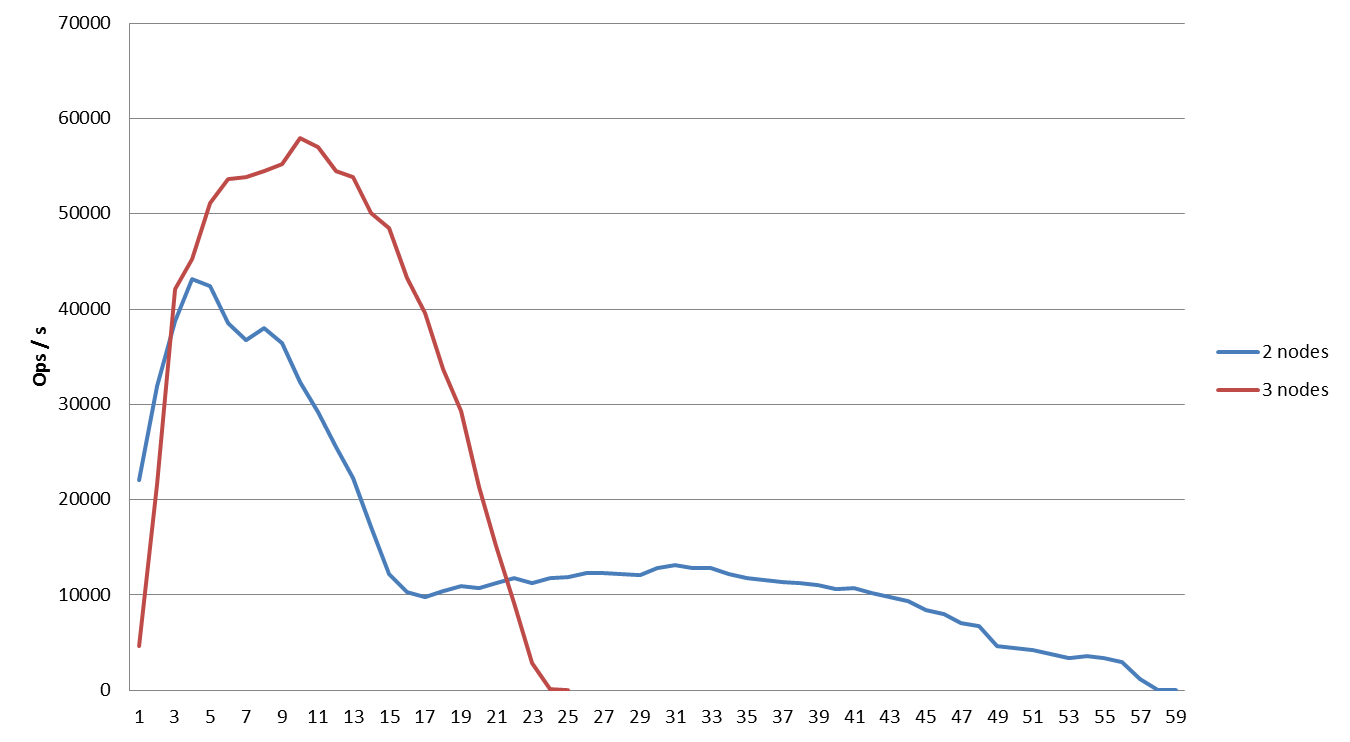
3 nodes yield better performance, as expected.
Comparing performance when exporting to 2 and 3 Couchbase nodes from 64 Hadoop mappers
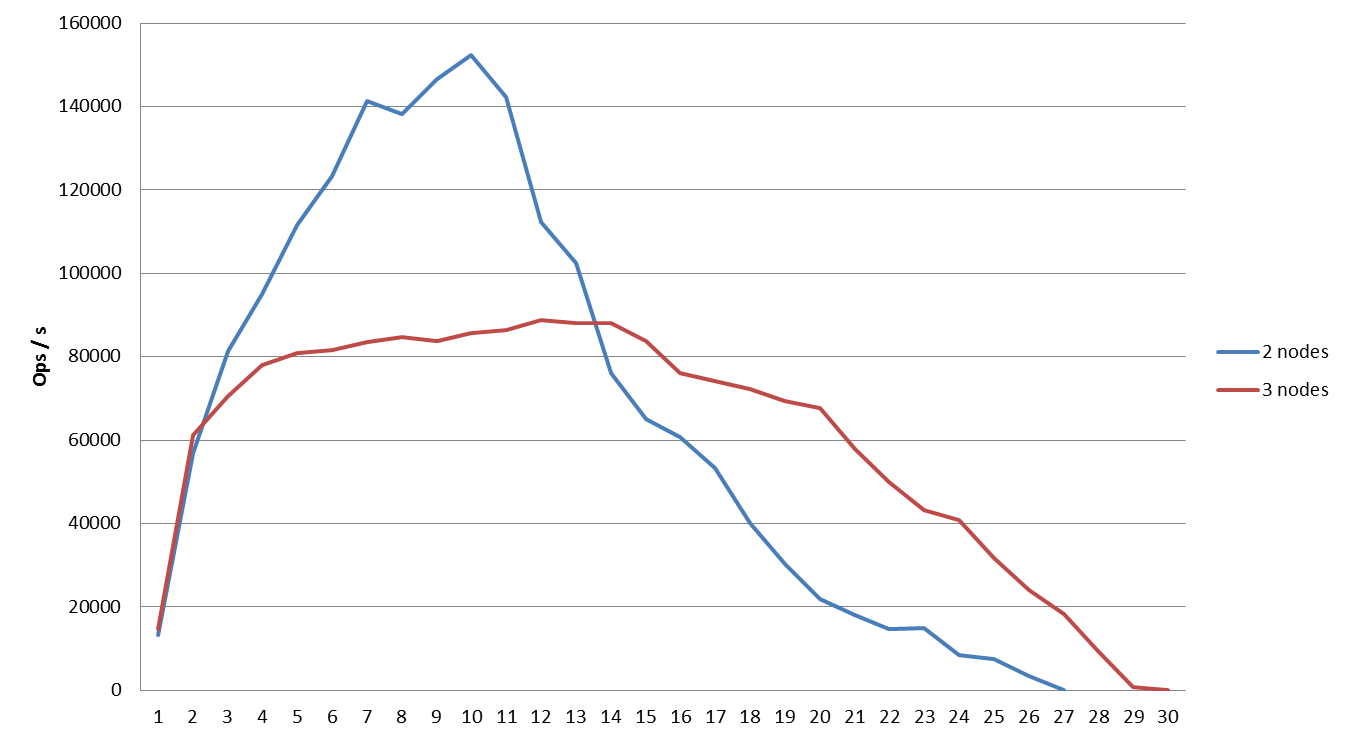
Comparing performance when exporting to 2 and 3 Couchbase nodes from 64 Hadoop mappers: with a higher number of Hadoop mappers, an increase in the number of Couchbase nodes actually decreases performance. This is a known issue for high contention clouds and we will explain the phenomena in the last section of this article.
Importing from Couchbase to Hadoop (3 Couchbase nodes)
1 Hadoop mapper
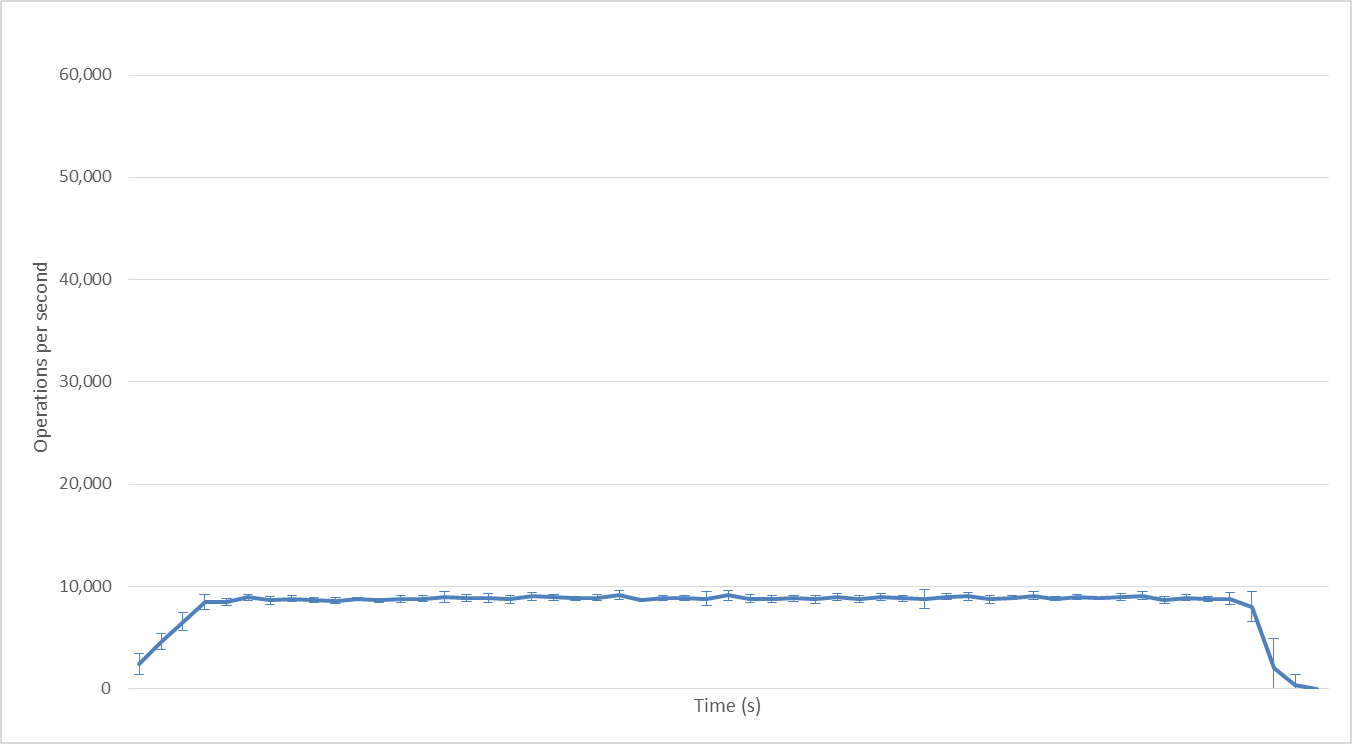
With 1 Hadoop mapper: no parallelism; 9000 ops/second.
2 Hadoop mappers
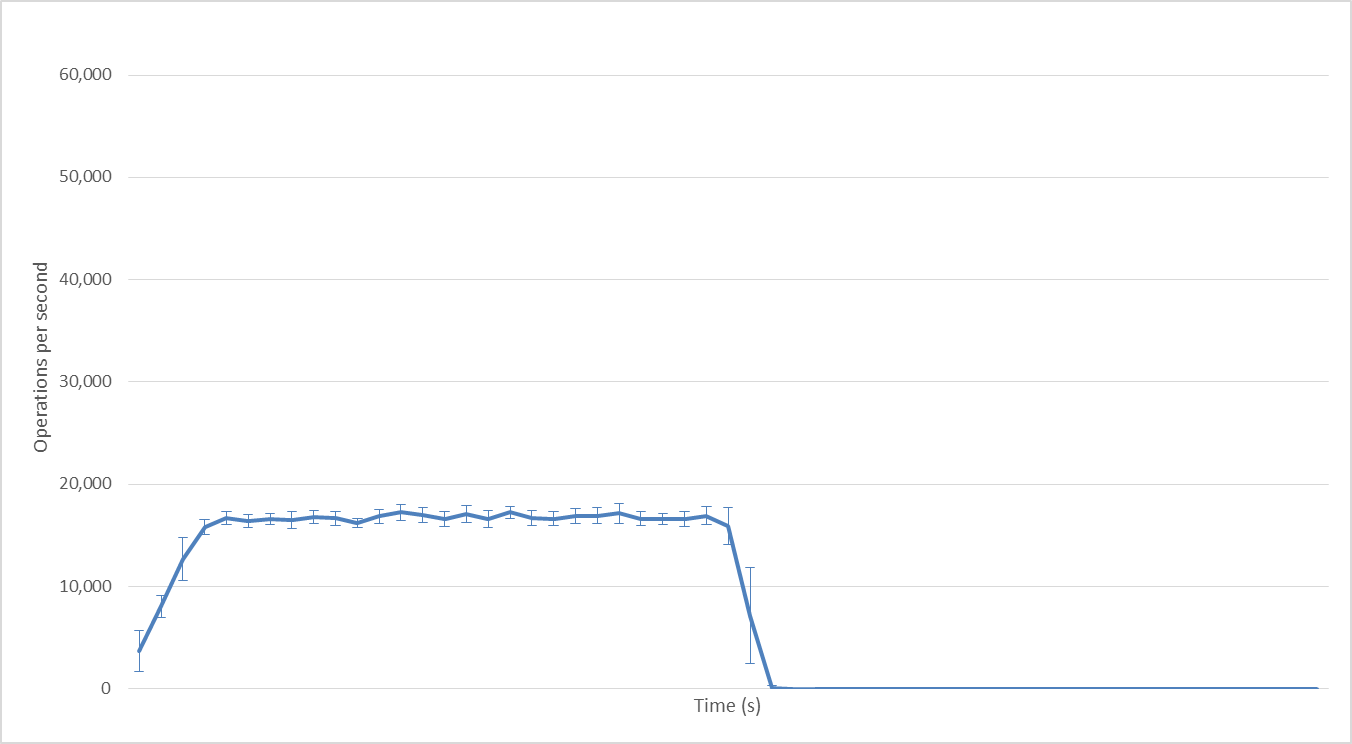
With 2 Hadoop mappers: we reach 17,000 ops/second; exactly what we expected. As before the increase is sub-linear but it goes on until we reach 64 mappers.
128 Hadoop mappers
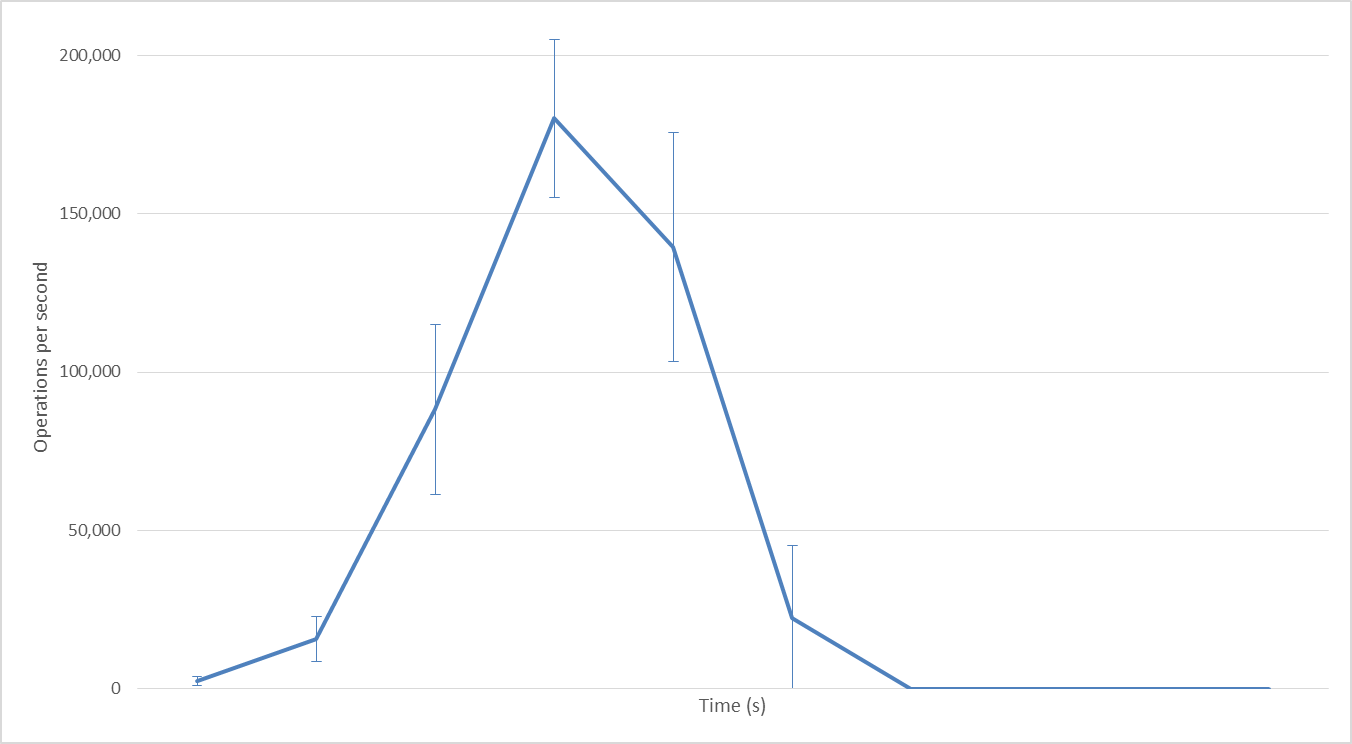
With 128 Hadoop mappers: 170,000 maximum ops/second, the same as for 64 mappers.
All imports from 3 Couchbase nodes
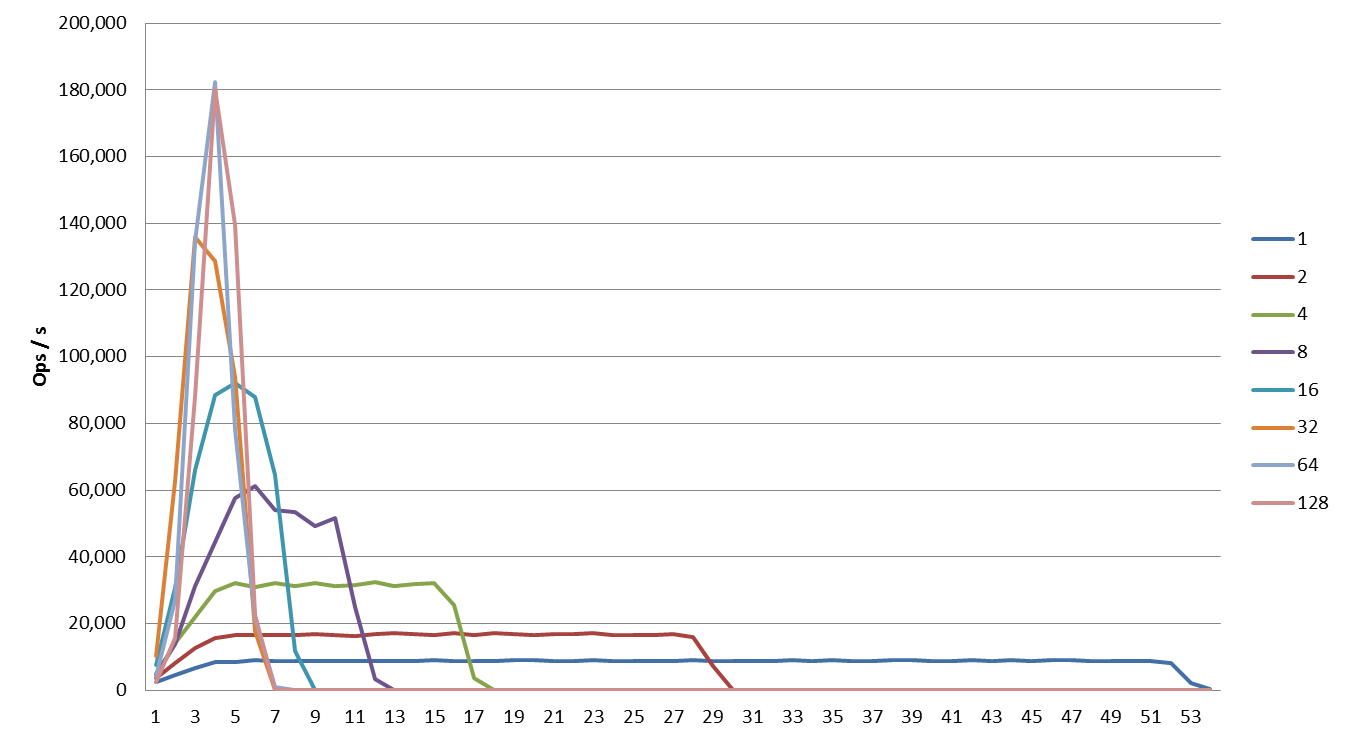
Here all imports are shown on the same graph. Performance benefits highly from increased parallelism but reaches it’s limit at 64 mappers.
Import performance dependence on the level of parallelism
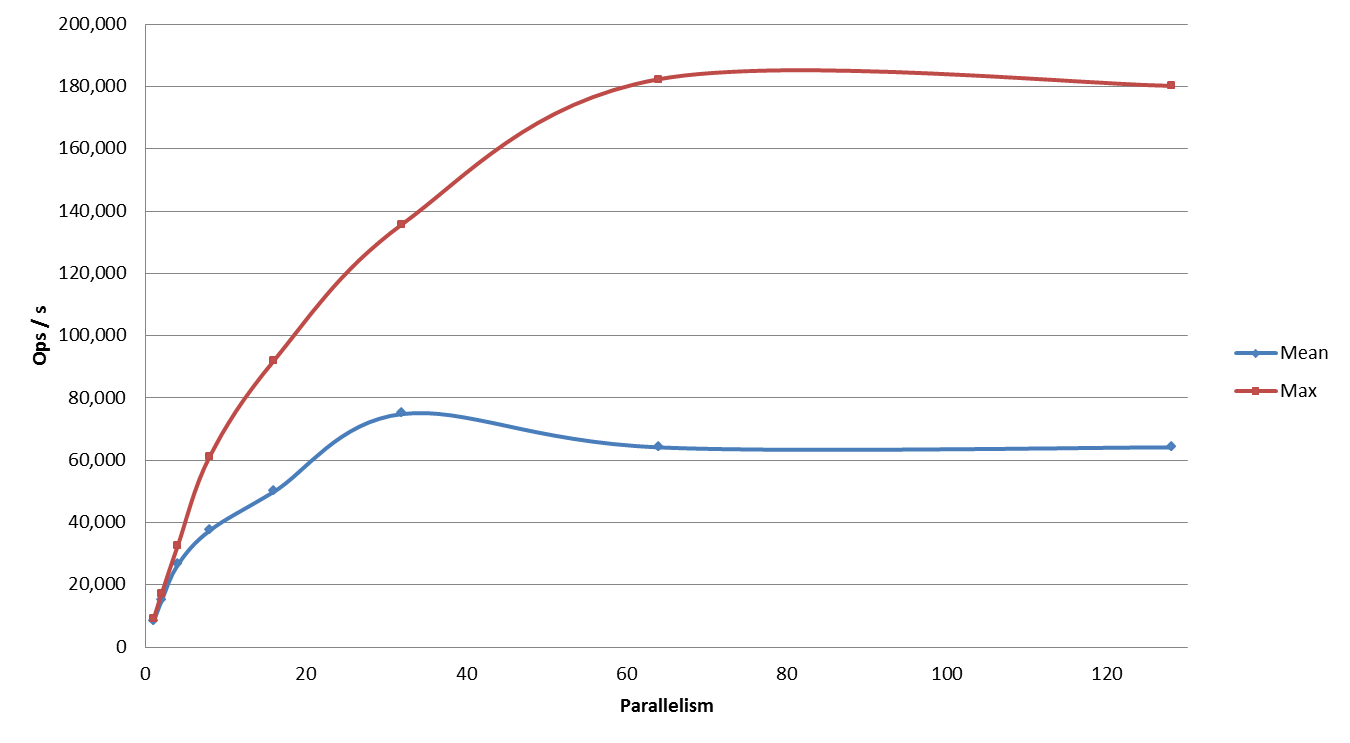
Import performance plotted against the level of parallelism. Highest mean performance was actually obtained with 32 mappers.
Comparing performance when importing from 2 and 3 Couchbase nodes to 4 Hadoop mappers
Comparing performance when importing with 4 Hadoop mappers: not much of a difference, but 3 nodes perform slightly better than 2 in this setup.
Comparing performance when importing from 2 and 3 Couchbase nodes to 16 Hadoop mappers
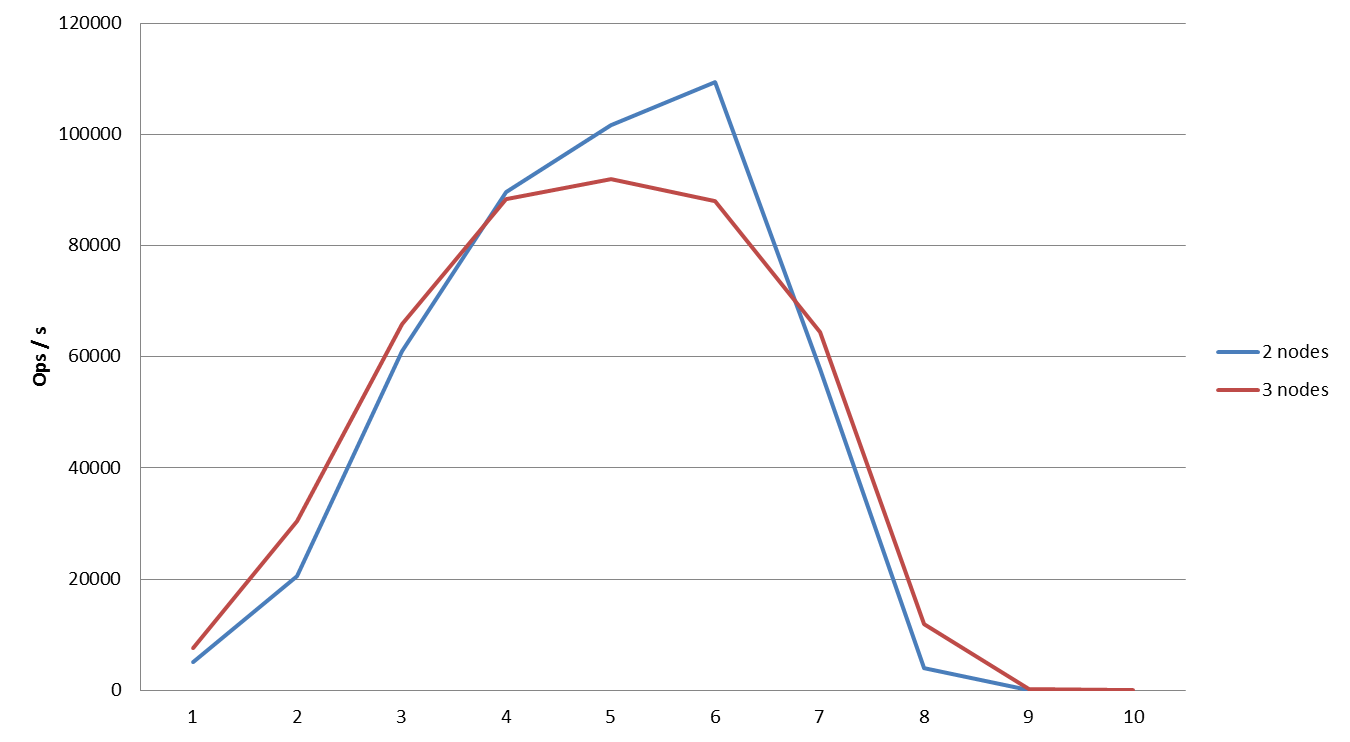
Comparing performance when importing to 16 Hadoop mappers: as before, once parallelism is increased above a certain point, we can obtain increased performance by removing Couchbase nodes.
Interpretation
Hadoop is out in the wild for some time and its performance in terms of scalability and throughput is well known. Couchbase is newer in the landscape and this experiment shows that it is able to achieve very high throughputs, about 350K operations per second for exports (750 MB/s) and about 185K operations per second for imports (400 MB/s). For the later, the limit is achieved at 80 mappers and above this value the performance actually starts to decrease. But for exports it seems that Couchbase’s limit is not yet hit. The limit is actually our Hadoop cluster which does not have enough YARN containers to allocate and some tasks wait for others to finish.
Network Shuffling Issue
As the experiments show when a many-to-many relationship is established between the data source nodes and the destination nodes a network shuffling occurs which causes a drop in the throughput. This issue is not particular to our software setup (Hadoop, Couchbase and Couchdoop), it is a common issue in today’s data centers and it is related to the network setup, which was designed in the past for enterprise or intranet traffic. Today’s cloud platforms host complex distributed systems which produce unpredictable intra-cluster traffic. A lot of research has been done on this topic and several infrastructure solutions have been found (see Hedera and MPTCP).
Data centers today use a multi-rooted tree of switches: there are top-of-rack (ToR) switches (usually cheaper and with a lower throughput), there are some aggregation switches, which connect ToR switches and one or more core switches, which connect aggregation switches. High-end switches from the top of the tree have a limited port density, have higher speed links, but as a consequence their aggregate bandwidth is lower. Between any two hosts from different racks there are multiple equal-cost paths. ECMP protocol is used to statically assign each flow to a path by using flow hashing. Unfortunately, the choice for a path is random and there is a high chance of collision, on at least one switch-to-switch segment. Additionally, a random choice is not able to account for network utilization of current flows. This causes a drop in the network throughput on the paths involved. Multipath TCP might provide a solution for future data centers.
We believe that the above mentioned issue is the reason why we experienced decreasing performance during the many-to-many communication, as parallelism increased. We are open for debate on this topic, so feel free to comment if you have other ideas.
Conclusion
Couchbase is able to achieve very high throughputs. Couchdoop provides a good solution when integration with Hadoop is necessary and by leveraging parallelism loading batches of data to / from Couchbase becomes a very fast process. If you experience the network shuffling issue, experiment with the level of parallelism in order to find to sweet spot were the best performance is achieved. Whatever you do, experiment!
Readers also enjoyed:

How To Benchmark NoSQL Databases


Leave a Reply
Your email address will not be published.